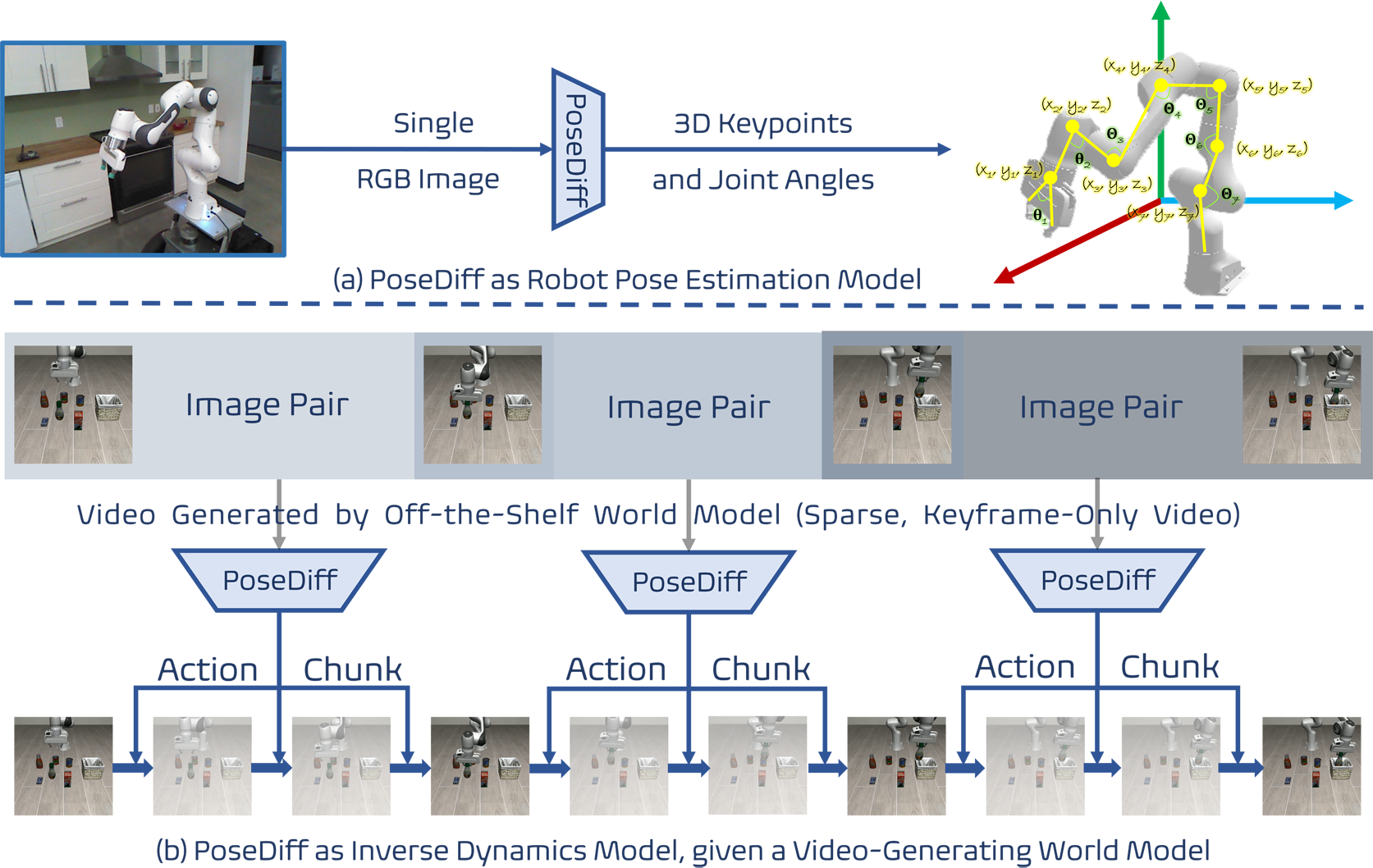
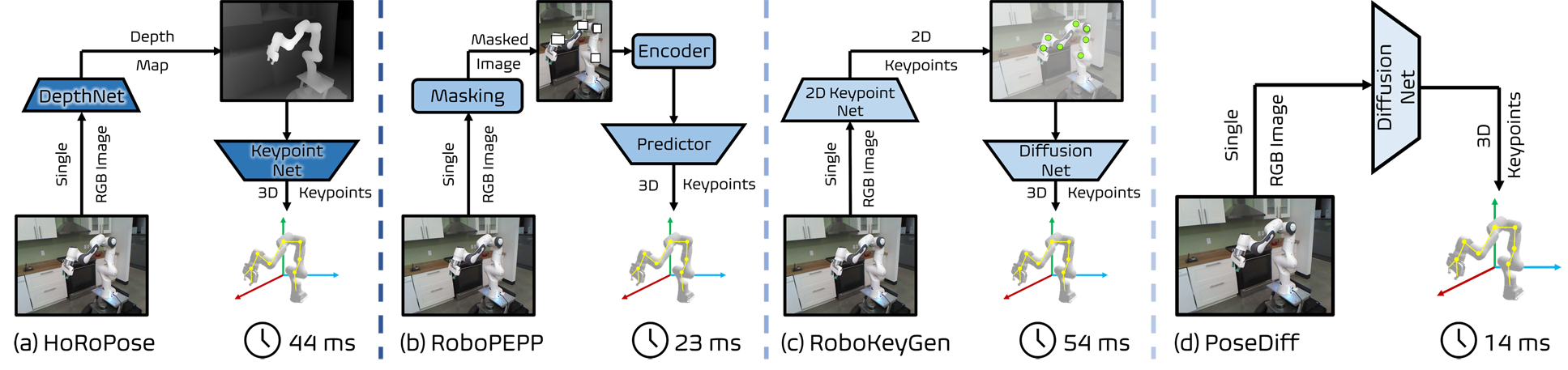
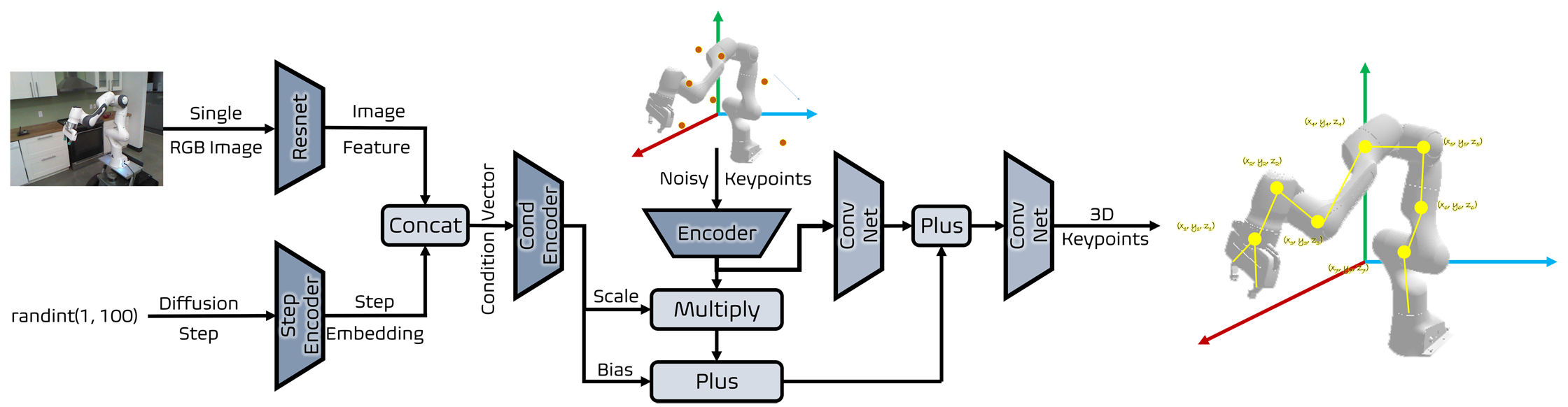
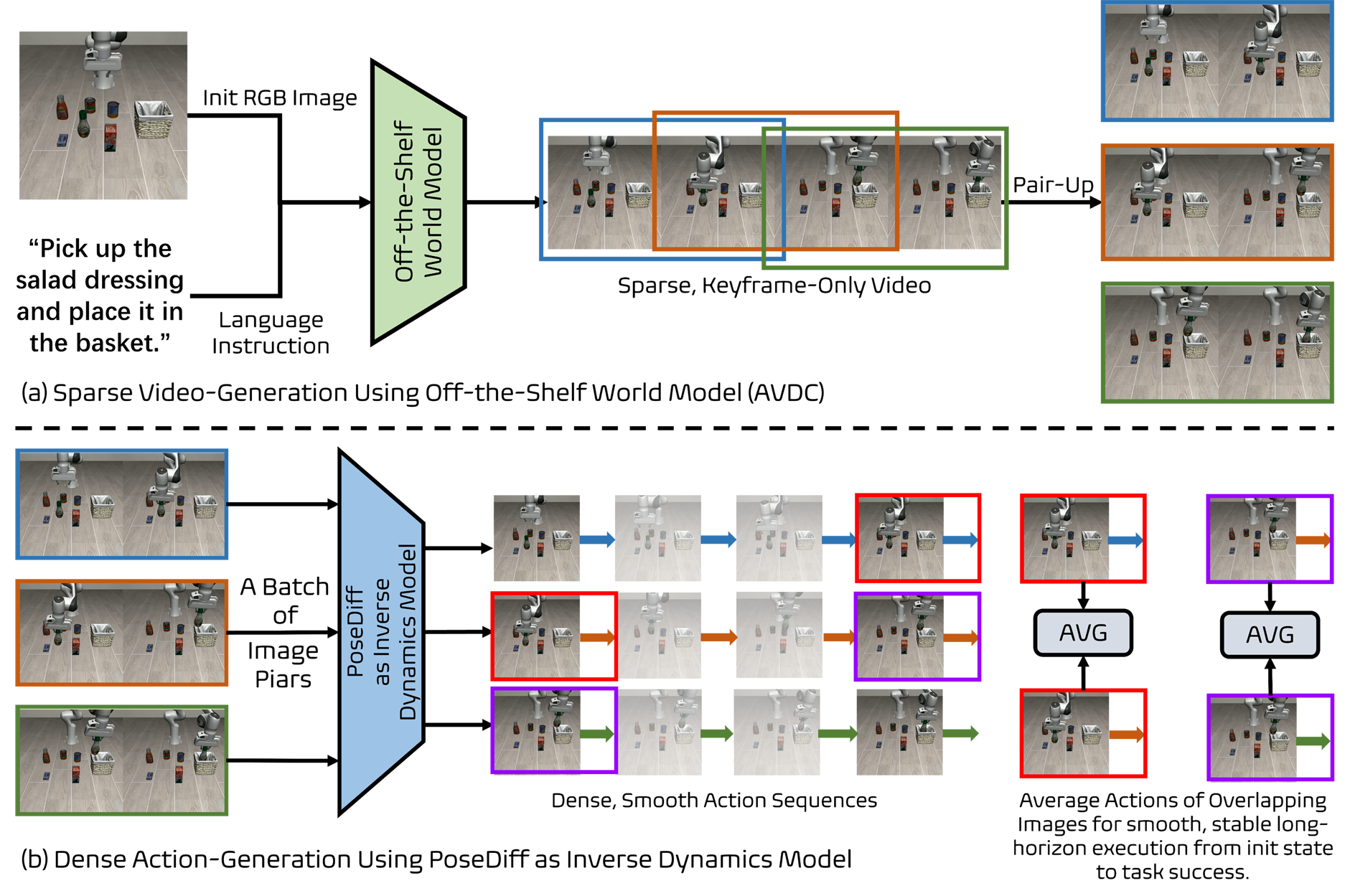
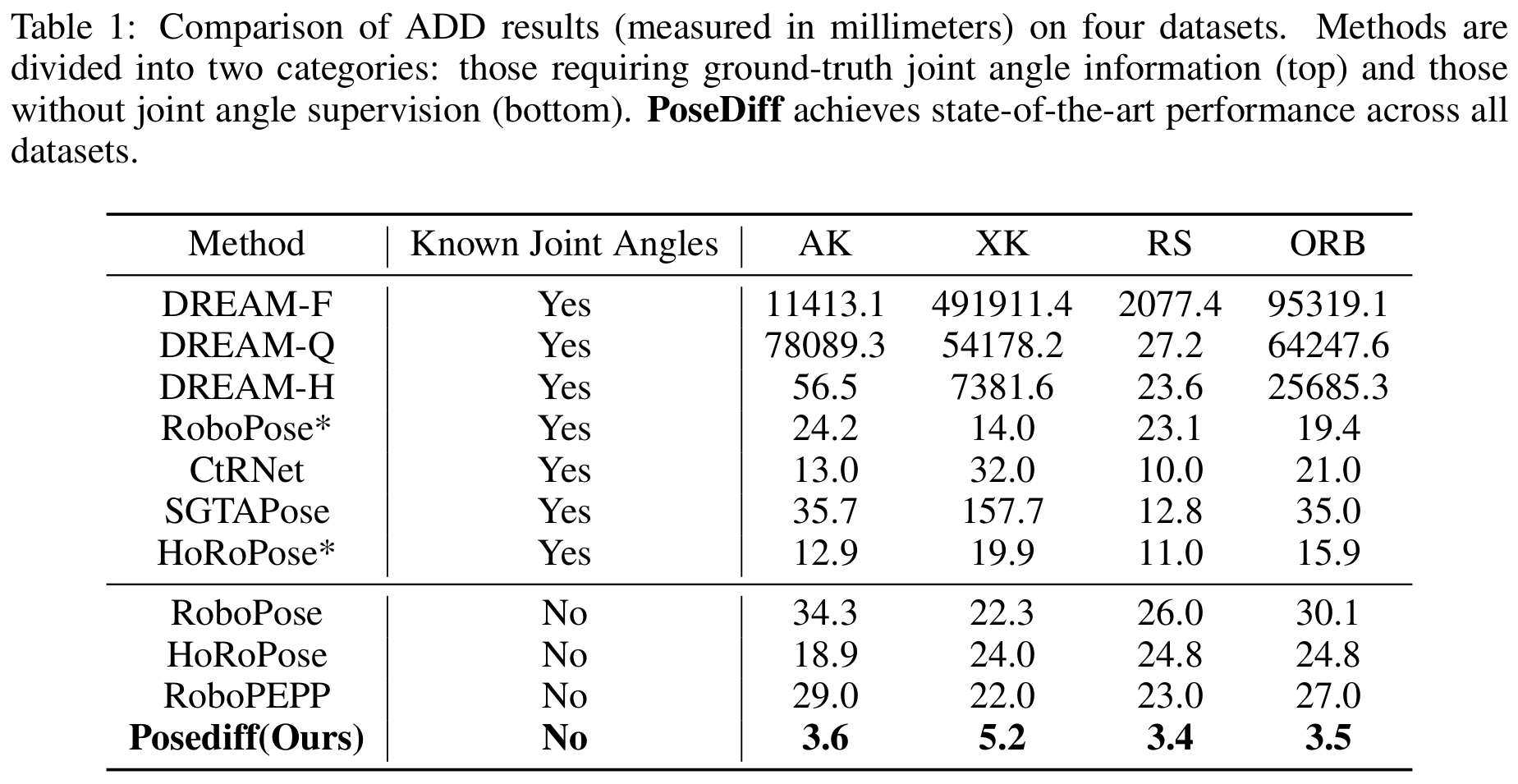
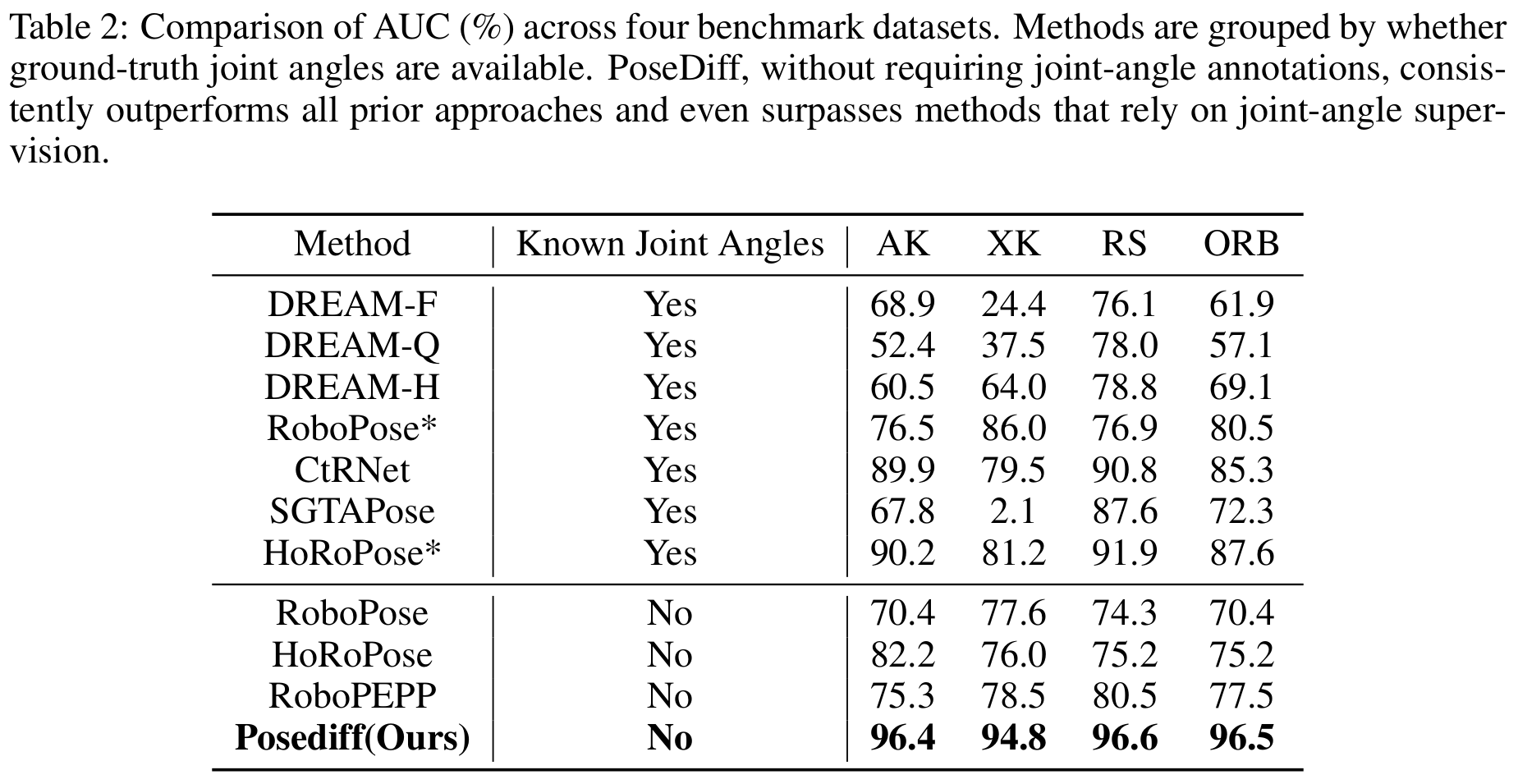
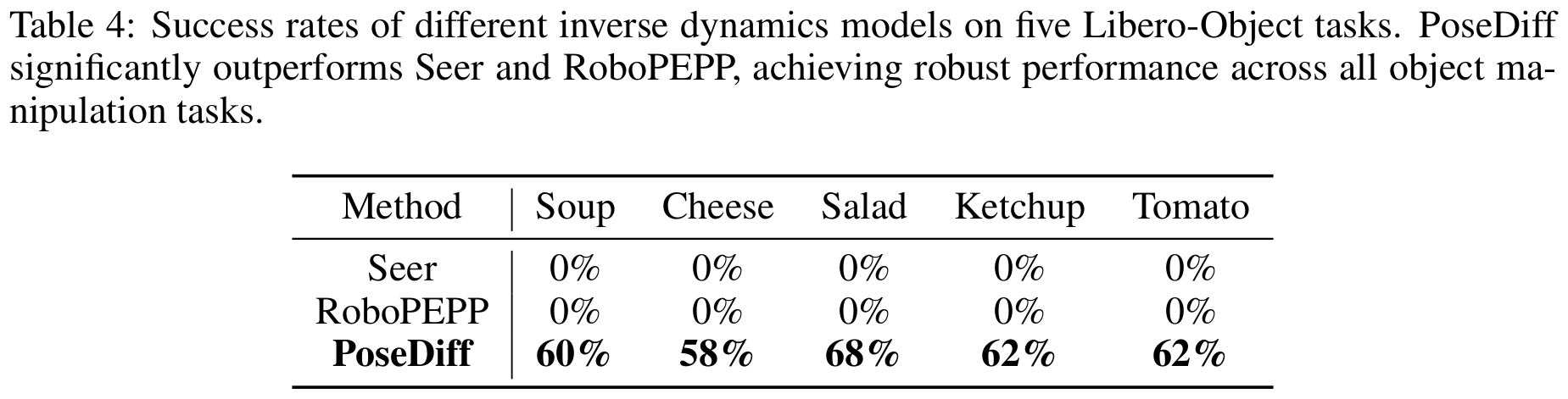
We present PoseDiff, a conditional diffusion model that unifies robot state estimation and control within a single framework. At its core, PoseDiff maps raw visual observations into structured robot states—such as 3D keypoints or joint angles—from a single RGB image, eliminating the need for multi-stage pipelines or auxiliary modalities. Building upon this foundation, PoseDiff extends naturally to video-to-action inverse dynamics: by conditioning on sparse video keyframes generated by world models, it produces smooth and continuous long-horizon action sequences through an overlap-averaging strategy. This unified design enables scalable and efficient integration of perception and control. On the DREAM dataset, PoseDiff achieves state-of-the-art accuracy and real-time performance for pose estimation. On Libero-Object manipulation tasks, it substantially improves success rates over existing inverse dynamics modules, even under strict offline settings. Together, these results show that PoseDiff provides a scalable, accurate, and efficient bridge between perception, planning, and control in embodied AI.

@misc{zhang2025posediffunifieddiffusionmodel,
title={PoseDiff: A Unified Diffusion Model Bridging Robot Pose Estimation and Video-to-Action Control},
author={Haozhuo Zhang and Michele Caprio and Jing Shao and Qiang Zhang and Jian Tang and Shanghang Zhang and Wei Pan},
year={2025},
eprint={2509.24591},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2509.24591},
}